
Chun-Feng Wu, Carole-Jean Wu, Gu-Yeon Wei, and David Brooks. 2022. A Joint Management Middleware to Improve Training Performance of Deep Recommendation Systems with SSDs. In Proceedings of the 59th ACM/IEEE Design Automation Conference (DAC) (DAC ’22), July 10– 14, 2022, San Francisco, CA, USA. ACM, New York, NY, USA, 6 pages. https://doi.org/10.1145/3489517.3530426
ABSTRACT
As the sizes and variety of training data scale over time, data preprocessing is becoming an important performance bottleneck for training deep recommendation systems. This challenge becomes more serious when training data is stored in Solid-State Drives (SSDs). Due to the access behavior gap between recommendation systems and SSDs, unused training data may be read and filtered out during preprocessing. This work advocates a joint management middleware to avoid reading unused data by bridging the access behavior gap. The evaluation results show that our middleware can effectively improve the performance of the data preprocessing phase so as to boost training performance.
INTRODUCTION
Deep recommendation systems are widely adopted to improve user experience across various web services, such as entertainment or e-commerce services. As the sizes and variety of training data grow, the performance bottleneck of recommendation model training gradually shifts from the model training phase to the data preprocessing and ingestion phase.
Data Ingestion:把 raw training data 從 HDD/SSD 讀入系統 DRAM 的過程。recommendation system 的 dataset 通常是 TB/PB 的等級,遠大於 DRAM 的容量,所以必須存在 SSD。
tensor 是張量,也就是多維陣列。
Data Preprocessing:資料進入 DRAM 後,需要將資料經過一系列的 decoding、decompression、filtering、feature extraction、normalization、再次 encoding、batching(GPU 的單次運算單位),轉成 tensors 之後才可以餵給 GPU。
For example, during model training, more than 56% of GPU cycles were idle and waiting for CPUs to handle training data preprocessing .
一個餵給 GPU 的 batch size = 2 的 tensor 可能長這樣: [[User_ID: 101, Item_ID: 50], [User_ID: 202, Item_ID: 88]]
如果 CPU ingest 和 preprocess 資料時間太久,那 GPU 會經常 idle。
We show that, due to the access behavior gap between recommendation model training and SSDs, a significant amount of the data preprocessing phase is spent on reading and filtering unused training data. To improve training performance by minimizing the needs of reading and preprocessing unused data, this work aims to bridge the access behavior gap by advocating a joint management middleware between a GPU-based recommendation training systems and SSDs.
The industry, such as Facebook, Baidu and Google, have adopted deep recommendation models to recommend e-commerce products to each users. Recommendation models comprise:
- Fully-Connected (FC) Layers: Handle dense features
- Embedding-table Layers: Look up the categorical features (usually represented by sparse vectors)
To improve the inference performance, several previous works focus on co-designing recommendation models with various accelerators (e.g., GPUs, TPU-like devices, or in-storage processors).
作者列舉了三種大家常拿來做 Co-design 的對象:
GPUs
特性:平行運算能力強。
Co-design:調整 Batch Size 一次塞一堆資料進 GPU 運算。TPU-like devices (Tensor Processing Units)
特性:Google 專門為 AI 發明的晶片,只懂矩陣運算。
Co-design:TPU 記憶體有限,所以模型結構不能太發散;或者專門設計成適合 TPU 脈動陣列 (Systolic Array) 的運算模式。In-storage processors
這是最特別的一個,也跟這篇論文最相關。傳統上 SSD 只負責存資料。要運算時,必須把資料從 SSD 搬到 CPU/RAM。
Co-design:在 SSD 硬碟裡面直接裝一顆小 CPU,那簡單的工作比如 Filtering 可以丟給 SSD 自己做,以省下大量的 PCIe 傳輸頻寬。
In addition to inference, improving the performance of model training on large-scale datasets is crucial to the success of products supported by deep recommendation models. Generally, there are two key phases for training:
- data preprocessing phase: transforms raw data from storage devices to materialized tensor data
- feature training phase: trains tensor data.
To support massive scale feature training, Baidu proposes a distributed GPU hierarchical parameter server. Aiming at improving the performance of feature training, cDLRM prefetches embedding tables from the host memory to GPU memory at runtime. In addition to feature training, as the sizes and variety of training data scale all the time, Facebook performs an end-to-end analysis in 2021 and shows that the data preprocessing phase gradually becomes the performance bottleneck of recommendation model training.
Industrial recommendation models require tens of petabytes of training data, and are constantly growing all the time. An ever-increasing memory capacity is required to hold all training data in memory. However, Dynamic Random Access Memory (DRAM) faces the scaling challenge and also the average DRAM price has increased several times in recent years.
目前主流的 AI 訓練主力是 NVIDIA DGX H100 或類似規格的伺服器,DRAM 頂多只有 2 TB。當然大公司肯定不會只有一台,都是用叢集。以 Meta 在 2022 年發表的 AI Research SuperCluster (RSC) 為例,規模約 2,000 台伺服器(共 16,000 張 GPU)。整個叢集總 DRAM 容量估算約是 。論文提到的推薦系統資料量:「Tens of Petabytes」就算把 Meta 整座超級電腦所有的 DRAM 全部清空拿來放資料(完全不留給 OS 或其他程式),我們連 1/5 的訓練資料都放不下。
A practical and cost-effective system configuration for a recommendation system is to cache the most recently used training data in DRAM to enjoy its fast response time, and store all training data in the flash-based SSDs to save the deploy cost.
Flash Memory 叫 flash 的原因是來自舛岡富士雄博士(發明人)的同事有泉正二的建議,因為這種記憶體的 erase 流程讓他想起了相機的閃光燈。以前的 EEPROM 如果要清除資料,必須一個 byte、一個 byte 慢慢擦掉,就像在黑板上寫滿了字,然後拿一個小小的橡皮擦,一個字一個字慢慢擦,速度非常慢。 舛岡博士的 flash 特點是允許電路一次性地把成千上萬個 cell 的電子全部洩洪掉。
Due to the design of flash cells, SSDs mainly suffer from limited lifetime and the lifetime becomes shorter when storing more data bits in a cell. Besides, SSDs can only update data out-of-place because data in the flash page shall be erased before written new data in it, but the erase granularity is around dozens times larger than a flash page (please find more details in Section 2.1.2). The out-of-place update means the data shall be read out from the flash page, updated and written to a new flash page. To make SSDs easily compatible with any systems, SSDs adopt the Flash Translation Layer (FTL) to hide these constrains from host systems. FTL comprises a wear leveler to level write accesses on all cells to avoid wearing out some cells earlier, and an address mapper to keep track of the address of the updated data without the intervention from host systems. FTL is a double-edged sword, managing SSDs without host intervention but suffering from weak integration between applications.
Based on our investigation, the access behavior gap between recommendation model training and SSDs may increase the time of reading training data from SSDs during data preprocessing phases. The access behavior gap is that recommendation systems read out whole features during the data preprocessing phase, but the data arrangement of SSDs is not aware of this access behavior and mixes key-value items belonging to different features in the same flash page. Under this access behavior gap, unused key-value items will be read from SSDs, increasing the overall read time while incurring wasted SSD bandwidth. To mitigate the data movement overhead, this paper proposes a middleware, namely rec-aware SSD data arranger, to manage SSDs by taking into account the behavior of recommendation model training. In particular, the proposed middleware comprises (1) a rec-aware data merger to pro-actively merge data belonging to the same feature without seriously hurting SSD’s lifetime, and (2) a rec-aware data pinner to smartly pin data in the write buffer to enhance SSD’s bandwidth utilization. The evaluation results show that our rec-aware SSD data arranger reduces the overall read time by 20%~38% over that of the Log-Structured Merge-Tree (LSM) based strategy adopted in Baidu’s recommendation systems. Our read throughput results are within 12% of the optimal case.
BACKGROUND AND MOTIVATION
2.1 Background
2.1.1 Data Preprocessing of Recommendation Training Systems
Recommendation systems suggest relevant contents to users by leveraging a large-scale training data corpus, such as the online shopping history or the rating of movies. Recommendation models are trained with relevant data stored in storage devices. However, training data read from storage devices cannot be naively fed into trainers (e.g. GPUs or TPUs). One of the reason is that training data will usually be compressed or serialized before storing on storage devices. The data preprocessing design is widely adopted (e.g., Facebook and Google) to extract and transform training data to tensor data that is subsequently ingested into trainers.
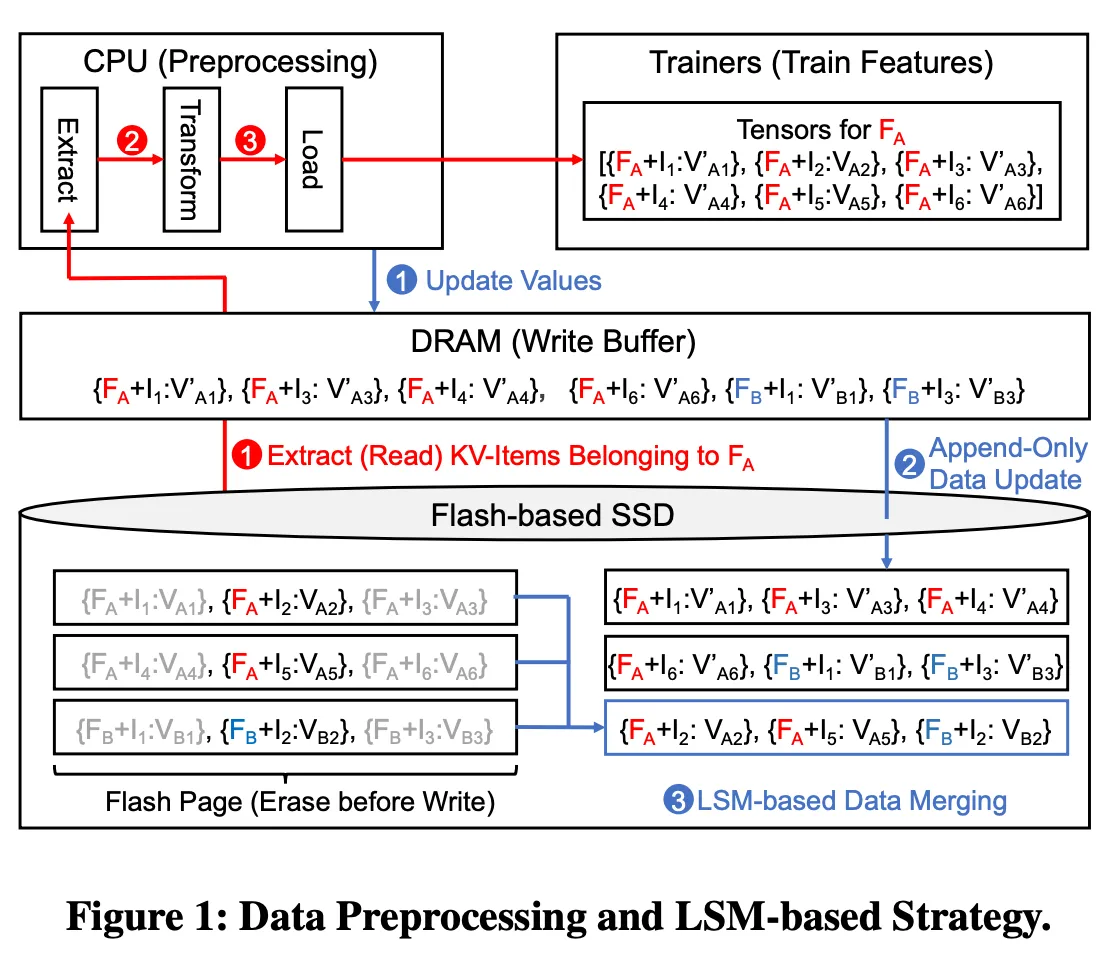
A conceptual data flow of data preprocessing is shown in Figure 1. A recommendation model is trained using multiple features. Each feature is associated with multiple key-value items (or KV-items for short), where each key represents an item and its value indicates the correlation between the item and the feature.
- :Feature,特徵名稱,例如「書籍的評分」。
- :Item,物件名稱,例如《哈利波特》這本書。
- :Value,具體數值,例如 4.5。
代表《哈利波特》這本書評分是 4.5。
For example, the average book ratings of users can be one of the feature, and each book item with its average ratings is stored as a KV-item. Assuming feature A () is selected for feature training in Figure 1. CPU reads out raw data (including all items and values) belonging to from storage devices (❶). However, due to mismatching formats, extra data including invalid or unused data will also be read out from storage devices (Details of extra data are introduced in Section 2.1.2). During the extraction stage (❷), CPU filters out the data belonging to unused features, and group KV-items for each feature. In the transformation stage (❸), each value will be transformed to the suitable format based on trainers’ requirements (e.g., sorting or normalizing floating numbers). Finally, features will be batched as tensors and loaded to trainers.
2.1.2 Solid-State Drives (SSDs)
With the advancement of manufacturing technology, die costs and the performance of flash-based SSDs have been improved year-by-year.
Die Costs:晶片製造術語。一塊完整的圓形矽晶圓 (wafer) 會被切割成無數個小方塊,每一個小方塊就是一個 die。die costs 指的就是製造這一小塊 flash memory 晶片的成本。隨著製程進步,我們可以在同樣大小的 die 裡面塞更多容量或者讓 die 變得更便宜,所以 SSD 的價格逐年下降。
In the rest of this paper, SSDs represent flash-based SSDs. SSDs are widely deployed in recommendation systems as the storage backend. In contrast to Hard Disk Drives (HDDs) which can update data in-place, SSDs shall update data out-of-place. Generally, the in-place update operation is realized by executing an erase operation to remove the old data and then running a write operation to write new data at the same place. However, due to the characteristic of flash cells, an erase operation cannot erase only one flash page, a minimum read/write granularity for SSDs, because the minimum erase granularity is a flash block, dozens times larger than a flash page.
Flash-based SSD 單位:
- Cell:最小的物理單位。想像 flash cell 是電子桶,裡面有沒有電子代表 1 或 0。
- Page:read/write 最小單位,通常是 4/8/16 KB。每個 cell 雖然有自己的 control gate,但因為電路設計限制所以動 control gate 就必須一次動一整排也就是一條 word line,這一整排就是一個 page。
- Block:erase 最小單位,通常是 2 MB。因為 erase 是對元件最底下的基材施加正電壓把電子從 floating gate 吸出來,但基材是一大片包含很多 page 的,所以 erase 會動到的資料又更多。
寫入是以 page 為單位,但擦除必須以 block 為單位。 如果你想修改 block A 裡面的 page 1,你不能直接對 page 1 放電(因為一放電,整個 block A 的 page 2 ~ 256 也會被清空),不僅沒效率又傷 SSD,因為 SSD 寫入次數是有限的。
補充:雖然我們常說「一條 Word Line = 一個 Page」,但在現代 SSD (TLC/QLC) 中,關係其實更複雜一點:
- SLC (Single Level Cell):一個 Cell 存 1 bit。一條 Word Line 等於 1 個 Page。
- TLC (Triple Level Cell):一個 Cell 存 3 bits,靠電壓分 8 個等級。這時候,同一條 Word Line 其實包含了 3 個 logical pages,當你對這一條 Word Line 施加電壓時,你其實是在操作這 3 個 Pages 的資料。
Without executing erase operations, a common way to update data in SSDs is to do the Read-Modify-Write (RMW) operation, that is to read out flash pages containing the old data, modify all old data to new data, and write all modified flash pages to other free space. With using RMW operations to update data, the minimum update granularity shall align with the flash page size (e.g., 16KB), even when an SSD controller intends to update only few bytes (e.g., 4 Bytes for each value) of data in a flash page. This exaggerated update amplification seriously hurts the lifetime of SSDs. Although systems configure a portion of the DRAM as a write buffer to collect updates, the update amplification can not be effectively alleviated, especially when the capacity of training data scales up.
To alleviate the lifetime issues caused by updating training data, systems usually employ the append-only Log-Structured Merge-Tree (LSM) based strategy. The bottom part of Figure 1 provides the conceptual procedures of the append-only LSM-based strategy. All updated training data will be buffered in the write buffer before being updated to SSDs (❶).
For example, in the write buffer denotes that the value of item 1 () belonging to feature A () is updated to . Instead of updating data in the SSD out-of-place, LSM-based strategy appends newly updated data to new flash pages ,
這一步是由 software middleware 執行,它會呼叫 syscall(例如 write())把 DRAM write buffer 的資料寫入 SSD。這裡的 software middleware 似乎指的是在 OS user space 運作的 KV storage engine,例如 RocksDB、LevelDB。
and marks the previous data as invalid in the software middleware (❷).
這裡的 software middleware 也是指 KV storage engine。
Practically, a batch of updated data will be written to SSDs as a file (usually aligns with the flash page size) and the software middleware keeps track of the metadata of each file (e.g., the amount of invalid data).
software middleware 就是全知者,它管理了所有 page 的 metadata。當 寫進 page 4 時,它會知道 曾經出現在 page 1,因此會把 page 1 的 invalid data count +1。
Due to the fact that, the invalid status of data is maintained in the software middleware , the SSD controller cannot know which flash pages contain invalid data.
To reclaim space occupied by invalid data, the LSM-based data merging is executed to merge files containing more than half of invalid data (❸). Practically, LSM-based data merging reads out the rest of valid data in the file (e.g. , , and ), sorts data by their keys, merges to a new file, and writes the file to new flash pages.
compaction(這裡提到的 merge)也是由 software middleware 執行,並且是非同步執行。software middleware 會監控每個 file(也就是它 maintain 的那些 pages),每次 DRAM SSD 寫入發生都會增加一定量的 invalid KV items。而當 invalid data 量達到一個閾值(例如 > 50%)之後就會觸發 compaction:
- 讀取所有
invalid data count超過一半的 files 到 DRAM,filter 出 valid KV items。 - 重新按照 key 字典序排序。(如果每個 SSD 內的 page 都已經按照 key 字典序排序了,那這裡排序其實可以做到 ,方法類似 merge sort 的雙指針)
- 再次 batch 這些資料,寫入 SSD 乾淨的 pages。
- Discard:對舊的 files 佔用的空間呼叫
TRIM指令告訴 SSD controller。 - Physical Reclaim:SSD controller 收到
TRIM後,會將舊 files 所在的物理 pages 標記為垃圾。實際的空間回收會等到 SSD 內部執行 garbage collection 時以 Block 為單位進行擦除。
2.2 Observation & Motivation
Although LSM-based strategy can recycle space occupied by invalid KV-items, it is not made aware of the access behavior gap between SSDs and the recommendation model training. The access behavior gap is that the recommendation model training reads out whole features during the data preprocessing phase, each of feature contains ten of thousands or even more KV-items, but the data arrangement of SSDs is not aware of this application behavior . Due to the unawareness, a LSM-based strategy may mix KV-items belonging to different features in the same flash page during data merging . For example, data belonging to feature A () and B () are mixed in several flash pages in Figure 1. Data belonging to occupies three flash pages even though only two flash pages are enough to store in the ideal case. In this example, all three flash pages shall be read out even when the training process only requires , and data belonging to are considered as unused data. Reading out unused data may increase the overall read size and systems require longer read time to get the required features. On the other hand, SSDs provide high bandwidth to increase read performance by reading out multiple flash pages simultaneously. However, reading flash pages with unused data wastes the bandwidth resources and hurts the throughput. Finally, reading unused data may increase overall read size and waste high bandwidth so as to increase the time for training recommendation models.
Experiment
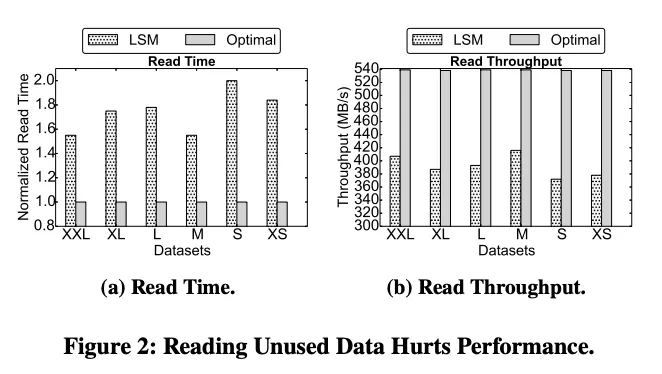
We build an emulator to validate that running a LSM-based strategy will mix data belonging to different features and thus degrades read performance. In this case, unused training data will be read during training recommendation models.
- We collect multiple recommendation datasets from Kaggle and build 6 synthetic datasets.
- The extra extra large (XXL), extra large (XL), large (L), medium (M), small (S) and extra small (XS) datasets have around 1.6, 0.8, 0.51, 0.31, 0.16 and 0.08 billions of training KV-items, respectively.
- Initialization: all items belonging to the same feature will be written to the SSD in a batch.
- Our emulator uniformly updates KV-items and triggers LSM-based data merging to merge files which contain more than half of invalid data.
- Our emulator will read out features from the SSD to simulate the behavior of recommendation model training.
(More details of the datasets and the experimental setups are provided in Section 4.1)
The evaluation results of both overall read time and read throughput are shown in Figure 2. Figure 2a illustrates that systems adopting the LSM-based strategy incur 1.53X ~ 2X longer read time than that of the optimal read case. This extra read time is caused by reading out 1.47X ~ 1.85X more data, where the data turns out to be unused. Moreover, reading un-needed data consumes additional bandwidth provided by SSDs and thus decreases effective bandwidth utilization. Based on our evaluation results shown in Figure 2b, the throughput of reading features from systems running the LSM-based strategy drops by around 22% ~ 31% compared with the optimal read case.
This work is strongly motivated by the urgent need to improve the read performance for recommendation training systems with SSDs. We propose a joint management middleware between recommendation systems and SSDs, so as to exploit unique access patterns of the recommendation model training (i.e. feature-based training) to facilitate the management of SSDs. Our ultimate goal is to:
- Improve the read performance by reducing the amount of unused data.
- Utilizing the high parallelism offered by SSDs.
SSD 跟 HDD 最大的不同之一就是 read/write 可以 multi-channel 平行處理。
The major technical challenge falls on:
- How to eliminate the access behavior gap by pro-actively merging data belonging to the same feature without seriously hurting SSD’s lifetime.
- how to improve SSD’s bandwidth utilization by smartly pinning data in the write buffer .
3 REC-AWARE SSD DATA ARRANGER
3.1 Overview
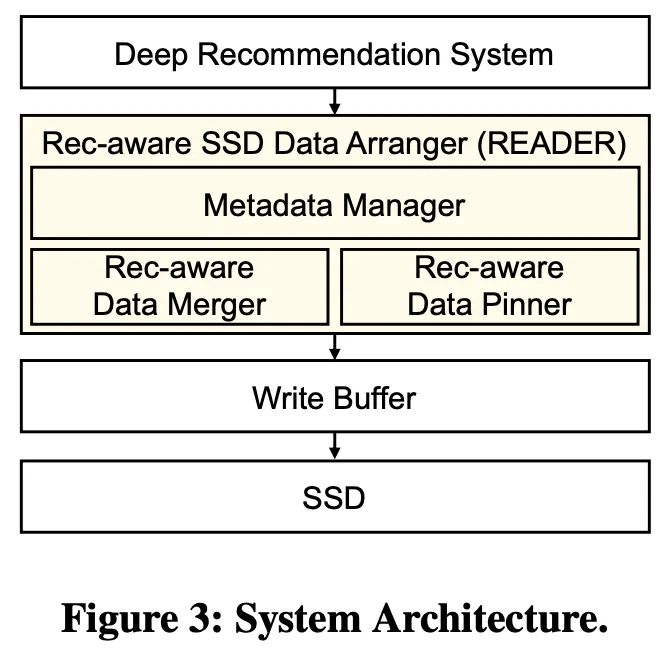
This section presents our rec-aware SSD data arranger (READER) to periodically rearrange KV-items stored inside SSDs with considering the recommendation model training behavior. As shown in Figure 3, READER is a middleware between the deep recommendation system and the SSD, and there is no modifications needed for both the recommendation training system and the FTL design inside the SSD.
FTL:Flash Translation Layer,SSD 的核心韌體,負責 address mapping(把主機的 LBA (Logical Block Address) 轉換成 PBA (Physical Block Address))、garbage collection、wear leveling(磨損均衡,因為每個 cell 都有 P/E Cycle)等。
- Section 3.2 presents two main data structures to keep track of the relation between each feature and its data arrangements in the SSD.
- Section 3.3 introduces the rec-aware data merger to merge scattered data belonging to the same feature.
- Section 3.4 then presents the rec-aware data pinner to improve bandwidth utilization by selecting frequently updated features and pinning data belonging to the features. Additionally, to avoid seriously hurting the lifetime of SSDs, updated KV-items will be buffered in the memory and appended to SSDs as a batch.
3.2 Metadata Manager
備註:原論文標題有 typo。
To bridge the access behavior gap between recommendation model training and the SSD, the metadata manager maintains two major data structures (as shown in Figure 4) to keep track of the relation between each feature and its data arrangements in the SSD, i.e., a feature table and a logical page table. Both of them are stored in storage devices and parts of these tables will be loaded and cached in memory on-demand for fast lookup.
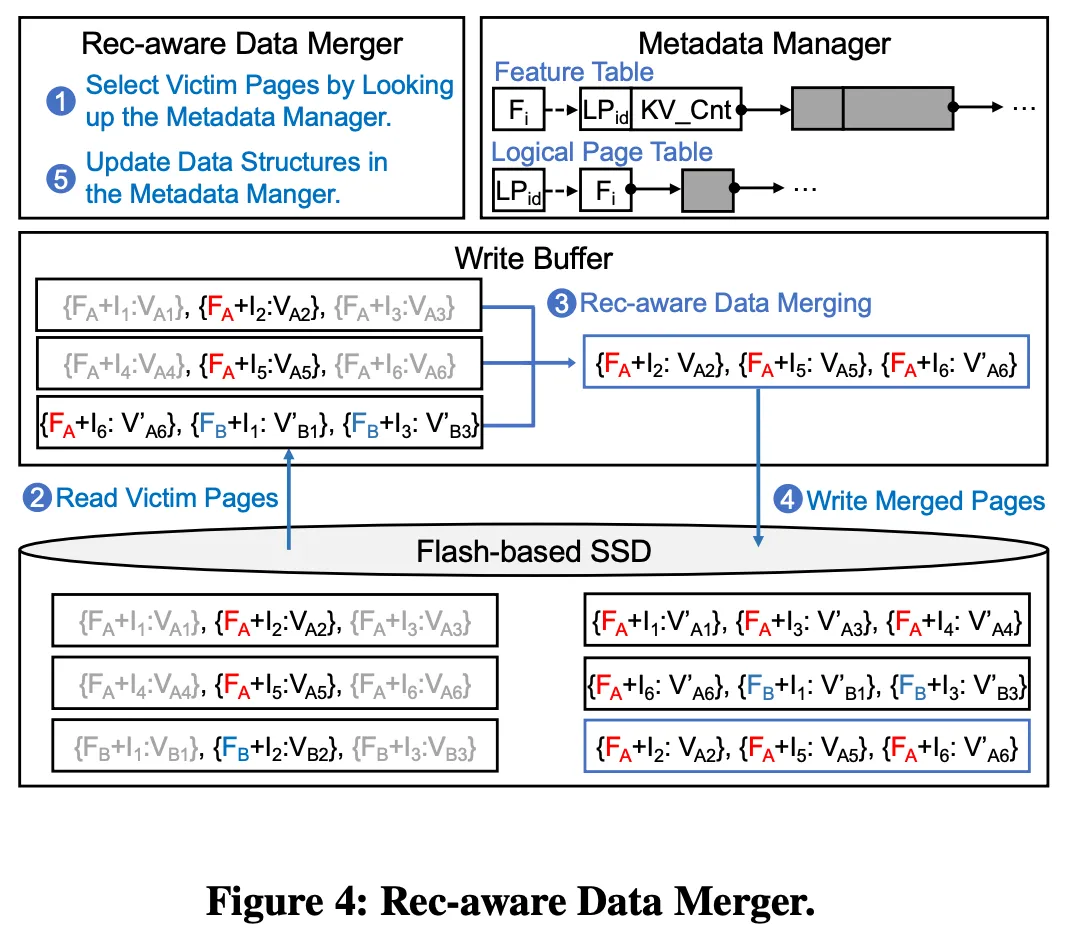
The feature table is a hash table, where:
key: a feature (i.e., )value: a linked list
Each node in a linked list stores:
- an id of a logical page (i.e., ) which accommodates KV-items belonging to the feature
- and a counter (i.e.,
KV_Cnt) to indicate the numbers of the KV-items in the page
FeatureTable = {
F0 : LinkedList(
Node(LP_id, KV_Cnt) -> Node(LP_id, KV_Cnt) -> Node(LP_id, KV_Cnt)
),
F1 : LinkedList(
Node(LP_id, KV_Cnt) -> Node(LP_id, KV_Cnt)
),
}Please note that, the size of a logical page is aligned with the flash page size.
To obtain KV-items belonging to a feature, our middleware traverses the linked list to find all corresponding pages, reads out all these pages to memory, and then looks up KV-items inside these pages byte-by-byte .
假設要抓 F0 的 KV items,那只要某個 page 包含至少一個屬於 F0 的 KV item 這個 page 就會被讀取。
This design can save a significant amount of space without maintaining an address for each KV-item especially when the size of an address is close to a KV-item. Even if each KV-item can attain an address, the corresponding page shall still be entirely read out because the minimum read granularity of an SSD is a flash page.
通常一個 KV item 跟位址指標大小是同個量級的,所以如果對每個 KV item 都要維護一個指標那記憶體 overhead 會非常高,再來就是 SSD 也只允許你一次讀一個 flash page(minimum read granularity)。
Thus, most of key-value databases designed for SSDs usually follow this design philosophy (e.g., LevelDB) to trade little read overhead for significantly minimizing the space requirements.
Additionally, controllers inside the SSD lack of the status information (i.e., valid or invalid) of each KV-item because both data updating and merging are controlled by our middleware outside SSDs. Thus, we also maintain a logical page table to keep track of the status information for each page.
The logical page table is a hash table, where:
key: an id of a logical page (i.e., )value: is a linked list chaining all features (i.e., ) whose KV-items are stored in this page.
LogicalPageTable = {
LP_id0 : LinkedList(
Node(F0) -> Node(F2) -> Node(F5)
),
LP_id1 : LinkedList(
Node(F1) -> Node(F2)
),
}When all KV-items in a page are marked as invalid:
- Remove all nodes (aka. features) from the linked list.
- READER notifies SSD’s FTL firmware to mark the corresponding physical page as an invalid page.
3.3 Rec-aware Data Merger
The proposed rec-aware data merger , as shown in Figure 4, is:
- Purpose: To merge scattered KV-items belonging to the same feature
- How to Achieve: exploiting the feature-oriented data structures maintained by the metadata manager. Our rec-aware data merger is activated when an updated KV-item is appended from the write buffer to an SSD.
As shown in Figure 4, there are two main stages of our data merger: (1) select victim features (❶), and (2) merge KV-items (❷ - ❺).
(Recall)
FeatureTable = {
F0 : LinkedList({ LP_id, KV_Cnt } -> { LP_id, KV_Cnt } -> { LP_id, KV_Cnt }),
F1 : LinkedList({ LP_id, KV_Cnt } -> { LP_id, KV_Cnt }),
}
LogicalPageTable = {
LP_id0 : LinkedList({F0 -> F2 -> F5}),
LP_id1 : LinkedList({F1 -> F2 -> F3 -> F4}),
}To select a suitable victim feature, our data merger looks up the feature table and picks the updated features whose feature-fragmentation degree is higher than a threshold. The feature-fragmentation degree indicates the ratio between the overall size of flash pages occupied by all KV-items corresponding to the feature and the total size of these KV-items.
Feature-Fragmentation Degree:為了讀取一個 feature 的所有 KV items,需要讀取多少 pages。這個數值代表讀取放大率。
當一個 feature 的 fragmentation degree 超過一定標準時,標記為 victim。這就表示這個 feature 的 KV items 太散亂了,需要進行 compaction。
To avoid hurting SSD lifetime, instead of merging all KV-items belonging to victim features, our data merger will not merge KV-items located in the low-merging-benefit pages. A low-merging-benefit page indicates a page containing a lot of KV-items belonging to the victim feature .
原論文這裡提到的標準是超過一半。檢查方法是去看 FeatureTable[F] 這個 linked list 的 node 的 KV_Cnt。
Merging KV-items in the low-merging-benefit page has very limited improvement on read performance, but the merge traffics may degrade the lifetime of SSDs. Practically, our data merger judges whether a page is low-merging-benefit with regard to the feature by looking up the in the feature table.
After deciding the victim pages, our data merger reads out all victim pages from SSDs and merges KV-items belonging to victim features (❷ & ❸). Our data merger then writes the new merged pages to the SSDs, and updates both tables in the metadata manager (❹ & ❺).
SSD 裡面一開始有 5 個 pages,分別是左排的 3 個(假設由上至下依序編號為 M, N, O)與右排的上兩個(假設由上至下依序編號為 P, Q)。
假設 Merger 已經判斷出 feature A 的 fragmentation degree 過大(按照論文的公式我認為是 ,因為 feature A 實際有效的 KV items 只有 6 個,最優需要讀取 個 pages,然而現在卻有 個 pages (M, N, P, Q) 包含 feature A 的資料)
那麼合併方式是:
-
抓出所有 high-merging benefit 的 pages,也就是 M, N, Q,這幾個 page 包含 A 的資料比都只有 33%,然後讀進 write buffer。
-
iterate 所有 victim pages,取出所有 valid 的 feature A 的 KV items,batch 綁在一起寫回 SSD,過程中同時更新:
- feature table:把被 compact 的 page 從
FeatureTable[A]拔掉,對於寫回 SSD 的新 page 宣告一個 node 之後 append 到FeatureTable[A]。 - logical page table:對於被 compact 的 page,把 A 從
LogicalPageTable[該 page]拔掉。
- feature table:把被 compact 的 page 從
-
如果過程中發現一個 page 扣除掉 invalid KV items 與屬於 A 的 KV items 之後已經是空的了(也就是這個 page 不會再被其他 feature 需要,對應到 page M, N),那把這個 page 的編號通知 SSD 的 FTL 請它之後透過排程處理後續的 garbage collection。(SSD 雖然不知道哪些 KV item 是 invalid 的但應該要可以知道哪些 flash page 是 invalid 的吧)
3.4 Rec-aware Data Pinner
Gathered KV-items may be gradually mixed with other items belonging to different features until our data merger merges the feature again. We propose a rec-aware data pinner to avoid easily mixing KV-items belonging to different features during appending updated KV-items to SSDs. Our rec-aware data pinner:
- pins (or locks) updated KV-items belonging to a feature in the write buffer
- unpins items when the size of pinned items belonging to a feature reaches a threshold (e.g., 1/4 of flash page size).
With this design, items belonging to the same feature have higher probability to be stored in a same flash page so as to minimize reading unused data and improve the utilization of SSD’s bandwidth.
Specifically, our rec-aware data pinner pins updated KV-items belonging to features which have more KV-items in the write buffer. Practically, modern Linux kernel provides pin_user_pages() and unpin_user_pages() functions to pin and unpin user pages in the memory. Our data pinner maintains a rec-aware pin structure (as shown in Figure 5), which is a max-heap data structure, to keep track of new updated KV-items. Each node in the rec-aware pin structure contains two elements, the identification of a feature () and the number of corresponding KV-items (#Items) in the write buffer. The number of KV-items belonging to a feature is set as the key of the max heap structure.
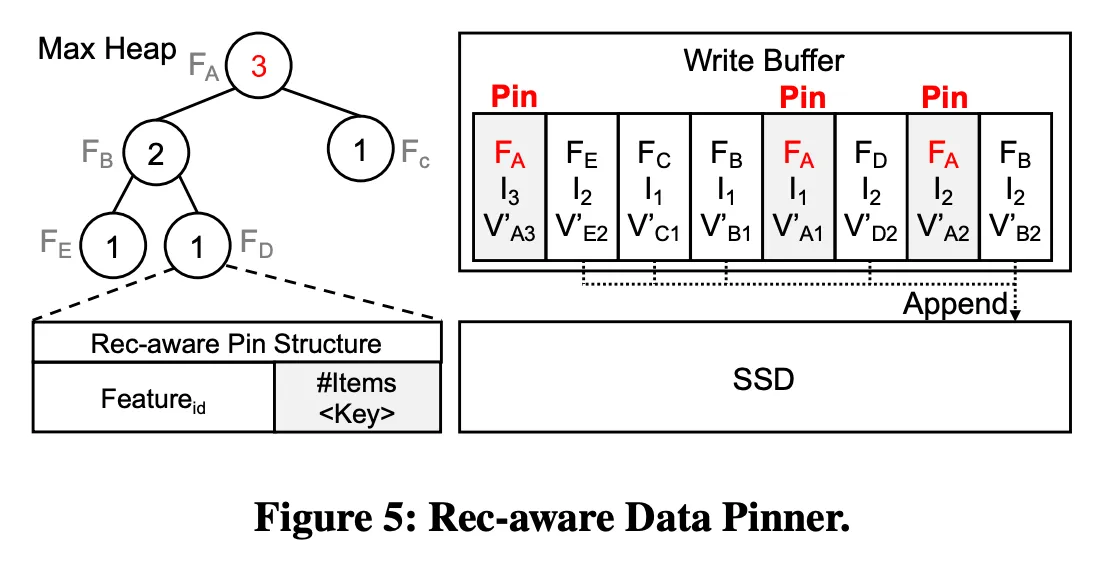
Figure 5 provides an example to show the interaction between our rec-aware data pinner and rec-aware pin structure. The rec-aware pin structure will be updated when an updated KV-item is added to the write buffer or appended to an SSD. Our rec-aware data pinner will select to pin KV-items belonging to the top-n features in the pin structure ( in this example). After that, our data pinner calls the kernel function to pin KV-items (i.e., , and ) related to selected features. Other non-pinned KV-items will than be appended to SSDs. Please note that, pinning too much items shrinks the available buffer size for new coming updated KV-items, and thus non-pinned KV-items belonging to different features will be mixed together easier. Based on our testing, to decide for top- features, we suggest to limit the overall pinning size to no more than 5% of the overall write buffer size .
graph LR
A[新 KV item 進 buffer] --> B{屬於熱門 feature 嗎?}
B -- "是" --> C[Pin 該 KV item]
C --> D{湊滿閾值了嗎?}
D -- 沒滿 --> C
D -- 滿了 --> E[unpin 該 feature 所有 pages]
B -- "否 (cold feature)" --> F[直接通過]
E --> G[Merger 接手]
F --> G
G --> H[執行 Rec-aware Merge]
H --> I[寫入 SSD]
4 PERFORMANCE EVALUATION
4.1 Evaluation Setup and Performance Metrics
This section evaluates the effectiveness of the proposed middleware for improving the feature reading performance of recommendation model training over SSDs, in terms of the overall read time and the SSD throughput .
Recall:Pinner 和 Merger 的目的,其實就是想「保留 Append 的寫入優勢,但同時盡量逼近 RMW 的讀取優勢」(透過延遲湊團來達成)。我猜這裡提到的 SSD throughput 是指 read throughput。
We evaluate both metrics by comparing the proposed rec-aware SSD data arranger (denoted as “READER”) with two baseline approaches. That is, the LSM-based strategy (denoted as “LSM”), which is adopted in Baidu’s recommendation systems, and the optimal read strategy (denoted as “OPT”). In contrast to append updated data to SSDs, the optimal read strategy runs RMW operations to avoid mixing items belonging to different features in the same page.
Optimal read throughput 就是不管其他成本,想辦法都要讓 read amplification 維持在 1,使用的方式是 RMW,每次更新一個 feature 的 KV item 都要把該 KV item 所在的 page 完整讀出來,然後寫一個完整的新的 page 回去,這樣的 write amplification 是 ,對 SSD 的壽命非常非常不利而且還會佔用 read throughput(但這篇論文的結果似乎是假設 OPT 的 throughput 仍然是 100%)。
Modern computer systems adopt write buffer to optimize the write operations. To provide further optimization for all approaches, all KV-items belonging to the same feature in the write buffer will be gathered and written to SSDs in a batch.
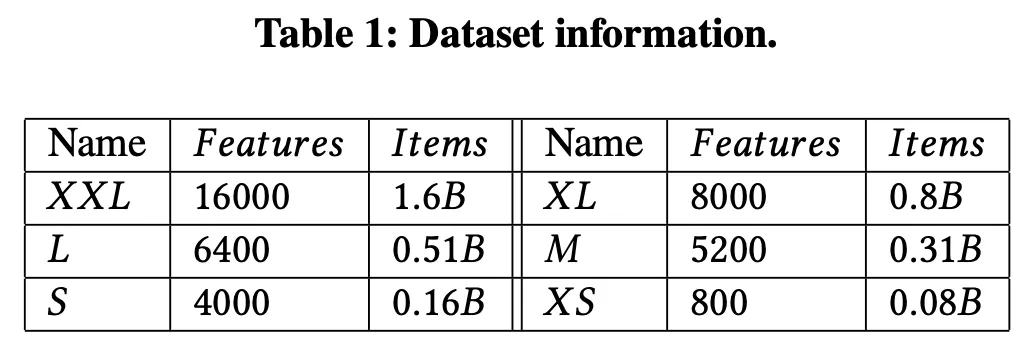
As shown in Table 1, we build six larger synthetic datasets by collecting multiple datasets from Kaggle (e.g., Goodreads-books, Top Games on Google Play Store, Hotel Recommendation, etc.). The extra extra large (XXL), extra large (XL), large (L), medium (M), small (S) and extra small (XS) datasets have around 1.6, 0.8, 0.51, 0.31, 0.16 and 0.08 billions of KV-items, respectively.
Experiment:
- KV-items belonging to the same feature are written to the SSD in a batch.
- Virtual write buffer: A suitable memory size (i.e., around 2.5% of the size of each dataset) is configured as a write buffer.
- For example, the write buffer can buffer around 2 millions of the updated KV-items for the large dataset.
- Please note that, we also provide results under smaller write buffer in Section 4.2.2.
- The emulator uniformly selects and updates KV-items in a dataset.
- Without loss of generality, the overall update counts are set to 800 millions to simulate that the systems have run for an enough long time.
- Read out features from the SSD to train different models required by various web services
- Totally read out around 60 thousands of features from the SSD.
- Due to the fact that the same feature will be selected to train different models, the total features read from SSDs are more than the feature in each dataset.
Testbed of the Experiment
- Emulator runs on HPE server.
- OS: Ubuntu
20.04.4
- OS: Ubuntu
- CPU: Intel® Xeon® Gold 6252n
- DRAM: around 380 GB
- SSD: Intel DC S4500
- Maximum Throughput: 540 MB/s
- Use “FIO” (version 3.16) with 64 queue depths to sent requests to the SSD for measuring the overall read time and throughput.
4.2 Evaluation Results
4.2.1 Evaluation on Read Performance and Lifetime.

Figure 6 provides the results of the read performance and SSD lifetime under running READER against the LSM-based strategy and optimal read strategy.
Figure 6a shows the evaluation of the overall read time, where the x-axis indicates six datasets and the y-axis shows the overall SSD read time caused by reading required features. The results show that READER can save 20%~38% of overall read time compared with the LSM-based strategy . The reason is that READER manages the arrangement of KV-items in SSDs by considering the recommendation model training behavior. That is, READER gathers KV-items belonging to the same feature in a flash page. With running READER, systems read out fewer unused data during recommendation model training compared with systems running the LSM-based strategy.
Figure 6b shows the throughput evaluation where the y-axis shows the throughput of reading the required features from the SSD. The result shows that systems with running READER can reach 1.16X ~ 1.33X higher read throughput than the LSM-based strategy . The results imply that running READER has better utilization of SSD throughput than that of the LSM-based strategy. Moreover, with running READER, the throughput results are within 12% of the optimal read strategy .
Although the optimal read strategy can provide the optimal read performance, it may seriously hurt the lifetime of SSDs. Figure 6c shows the lifetime evaluation, where the y-axis shows the update amplification.
- Definition of update amplification: Amount of extra data written to SSDs for updating per KV-item in average.
The results show that the optimal read strategy requires around 400 times of extra writes for updating an item, and both READER and the LSM-based strategy only need 1 extra writes for updating each item . The results imply that running READER can improve around 400 times of SSD lifetime compared with using the optimal read strategy.
4.2.2 Read Performance under Smaller Write Buffer.
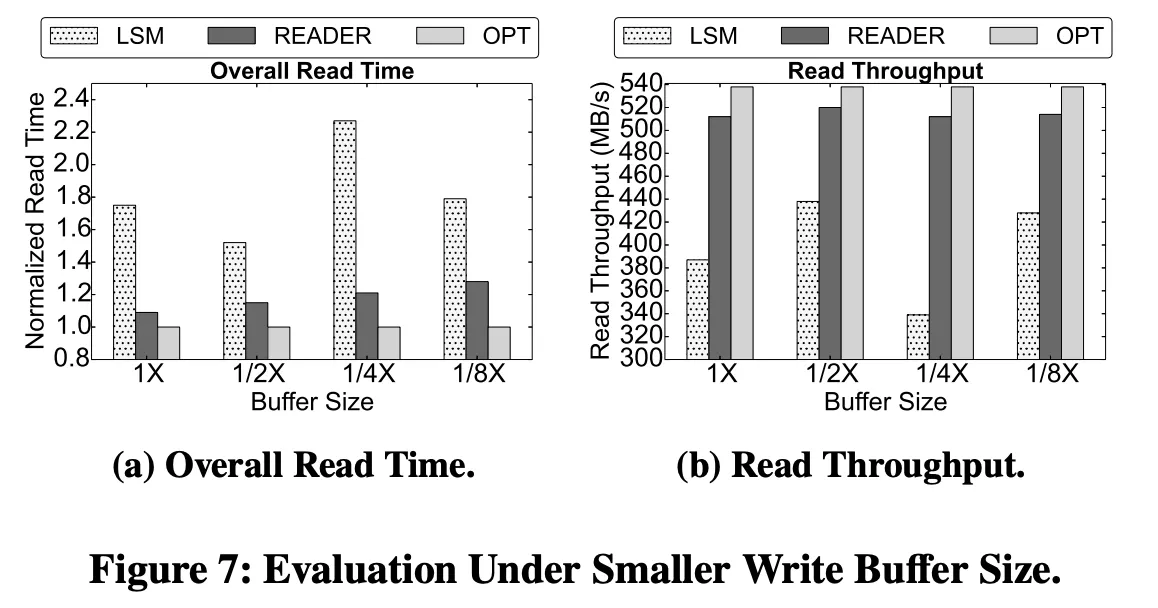
Figure 7 shows that READER is also effective and stable compared with the LSM-based strategy on systems with smaller write buffer. With considering the deployment costs, small and medium-sized enterprises or even personal customers may tolerate fewer performance degradation by shrinking the size of write buffer. Figure 7a shows the evaluation of overall read time on the XL dataset , where the x-axis shows the relative size of the write buffer compared with the size used by training the XL dataset and the y-axis shows the normalized overall read time. The results show that READER can save 24% ~ 47% of overall read time compared with the LSM-based strategy . Moreover, the design of the LSM-based strategy is not aware of the behavior of recommendation model training so that the overall read time seriously fluctuates . Figure 7b shows the throughput evaluation, where the y-axis shows the read throughput. The results show that READER can reach 1.19X ~ 1.51X higher read throughput than the LSM-based strategy .
5 CONCLUSION
Aiming for minimizing reading the amount of unused data from SSDs during recommendation model training, the paper presents a joint management middleware, namely rec-aware SSD data arranger (READER), to rearrange data in SSDs with considering the behavior of recommendation model training. READER comprises a rec-aware data merger to pro-actively merge data belonging to the same feature so as to avoid reading unused data from SSDs during training, and a rec-aware data pinner to smartly pin data in the write buffer so as to better utilize SSD’s bandwidth. The evaluation results show that running READER can save the overall read time by 20% ~ 38% compared with the LSM-based strategy, and our read throughput results are within 12% of the optimal case.
6 ACKNOWLEDGEMENT
We would like to thank Yunho Jin, Samuel Hsia, Udit Gupta, Mark Wilkening and Jeff (Jun) Zhang for their thoughtful comments and suggestions. This work was supported in part by the Ministry of Science and Technology, Taiwan, under Grant No. 110-2917-1-564-025, the Application Driving Architectures (ADA) Research Center, a JUMP Center cosponsored by SRC and DARPA.